OSHIT: Seven Deadly Sins of Bad Open Source Research
When news breaks and the internet is aflutter with activity and speculation, many turn to open source accounts and experts to make sense of events. This is truly a sign that open source research — using resources like satellite images to flight tracking websites and footage recorded on the ground — is seen as credible and is increasingly sought after. It’s free, publicly available and anybody can do it.
But such success comes with drawbacks. In monitoring events from Iran and Ukraine, this surge in credibility allows the term ‘OSINT’ to be easily abused, either knowingly or unknowingly, by users who don’t actually follow the best practice of open source research methods. In fact, since the start of the war in Gaza in October 2023, there has been a spike in verified ‘OSINT’ Twitter accounts which create additional noise and confusion with poor open source analysis.
Conducting open source research properly isn’t about being ‘verified’ or having a huge following. It isn’t about expecting people to take your word for things. It’s about collaboration and sharing the skills necessary to independently verify what you see online. It’s about showing your working and the origin of your data so that anybody can replicate your methodology.
As Bellingcat’s Giancarlo Fiorella indicated in the Financial Times in December, open source research is critical in the long term when it could come to play a role in prosecuting those responsible for atrocity crimes. That raises the bar significantly — not just for the sake of the open source research community as a whole, but also for that of accountability for the victims of armed conflicts.
Here are a few mistakes we’ve noticed from open source researchers in recent years. Many examples are relevant to monitoring armed conflict, but could broadly apply to any genre on which open source research shines — such as natural disasters or organised crime.
We work in a young and rapidly evolving field, facing a deluge of information. Mistakes should be no cause for surprise or shame. Everybody makes them. But a good open source researcher is open about doing so – they correct their errors quickly and vow to do better next time.
If you’re a reader, looking out for these ‘Seven Sins’ (listed in no particular order of gravity) will help you independently judge the quality of open source research you encounter online. If you’re also an open source researcher, looking out for them will help improve the quality of your own work.

1. Not Providing the Original Source
The main tenet of open-source research is that it’s ‘open’: ideally the information is publicly accessible and used in a transparent way. This allows anyone to verify the sourcing and veracity of a piece of footage, without having to trust the person who posted it.
In the wake of Russia’s full-scale invasion of Ukraine in 2022, many “OSINT aggregator” accounts developed large followings on Twitter, mostly reposting videos from Telegram, often without linking to the video’s original source. When someone posts a video without saying where they got it from, verification becomes much more difficult; researchers can’t just follow a chain of links to its origin.
Without any clues as to who originally uploaded that video, we lose potentially crucial information about its content. Though most social media platforms strip metadata, for some platforms such as Telegram and Parler retain it. Such image metadata has played important roles in Bellingcat investigations on subjects from QAnon’s origins to Russian disinformation in Ukraine. This means that first instance of a photo or video may also contain metadata which is lost when the content is reuploaded, shared or compressed.
Bear in mind that there are circumstances when it can be ethically fraught to provide a link, such as if doing so would amplify hateful accounts or drive traffic to graphic content content. Nevertheless, a rule of thumb is to share when you can.
That’s because sharing the origin of a piece of content is a greater contribution than keeping it to yourself — the better to hoard future ‘discoveries’.
2. Letting Cheerleading Undermine Your Work
While everyone has bias, it’s important for open source researchers to attempt to separate these biases from the evidence that they examine. Though many open source researchers or communities clearly use these techniques in aid of a certain cause, they should still acknowledge when their sources or research don’t support that cause, and always be transparent about the level of uncertainty.
Confirmation bias is our tendency to accept as true any new information that confirms what we already ‘know’ to be true, and to reject new information that contradicts our beliefs. Just as everyone has bias, everyone is liable to fall victim to confirmation bias.
Nevertheless, the quality of open source research can be judged independently of political or social position. This is why the caveats are so important. Open source information doesn’t show everything, and may not prove whatever larger point you would like it to.
Acknowledging what you don’t know and what you can’t know is crucial for building trust — even if you have very clear and very public positions. Failing to do this can result in erroneous and self-serving investigations.
3. Not Archiving Material
Online content is often ephemeral: the internet is littered with links to pages that no longer exist. This could be because the owner of the web domain stopped paying their bills. It could be because the website changed how they organised pages. A content hosting platform could have decided to delete large amounts of their files, whether on purpose or by accident. Social media posts are often deleted, whether by the account who created the post, or by the social media platform’s moderation team.
That makes the work of open source researchers much more difficult. It’s why Bellingcat frequently emphasises the importance of archiving online content and has developed tools for making this easier.
The most trustworthy way to archive content is with third-party archiving platforms like the Internet Archive’s Wayback Machine or archive.today, though they often fail to correctly archive content from several social media platforms, as well as videos in general. If all else fails, a screenshot is better than nothing.
4. Lacking Context for Occurrences, Common or Otherwise
Particularly in the context of conflict monitoring, events that occur on a regular basis are often taken out of their original context and overblown. For example, researchers unfamiliar with reading NASA FIRMS images and data, may interpret regular, planned and controlled fires or other thermal changes as something more malicious. But in moments of tension, people unfamiliar with such common events may give them undue significance.
A recent example of this trend was when famous baseball player Shohei Ohtani was going to join a new team, leaving the Los Angeles Angels. In December 2023, a private flight leaving Anaheim in the US state of California for Toronto, Canada spurred online sleuths to believe that this was evidence of Ohtani meeting and potentially signing with the Toronto Blue Jays. when In reality, the flight was carrying a Canadian businessman and had no connection to Ohtani or baseball in general.
Distinguishing between common and uncommon events can take a lot of domain-specific expertise, whether that field is conflict monitoring, natural disasters, or any other area of research. Many researchers do not have this specific expertise regardless of how well they have mastered a tool or method.
5. Incorrectly Using Tools and Interpreting Data
There are many different open source tools out there, and we even try to keep a list of useful resources in Bellingcat’s Online Investigation Toolkit. However, as with any new tool, users often need some guidance, experience and training to master it.
We often see new users not being aware of these tools’ limitations. New tools aren’t silver bullets and they often come with many caveats. For example, for facial recognition software, there are strengths and weaknesses for different services and results provided by those tools should not be treated with complete certainty. Usually other data points and context is required to show why the match is credible. Depending on the photo and the particular case, it is possible to pursue false leads and come to incorrect conclusions based on the limitations of that software.
Tools which detect photo manipulation are another example. Last May, Colombia’s president retweeted an account who had improperly used one such tools, drawing overconfident and incorrect conclusions.
Even when such tools have been mastered, it takes time to learn how to interpret the data or results they generate. In one example, drone footage of a fast moving object was interpreted as a UFO when in reality it may have just been a balloon.
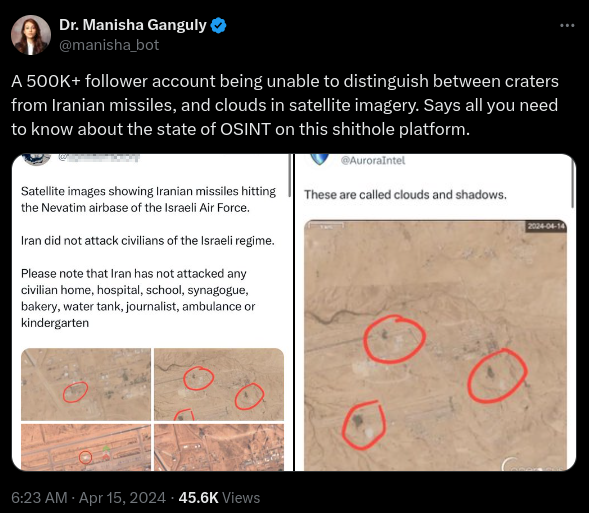
In another, a user mistook clouds on satellite imagery for craters.
6. Editing Footage
While usually not done maliciously, OSINT accounts sometimes edit footage in an unhelpful way, such as placing an audio track over the video, making a compilation of clips, or trimming down the original footage.
For example, one habit of ‘aggregator’ accounts is to overlay their channel’s watermark over videos and images. If we can’t find the origin of a video, we generally perform a reverse image search of frames from the footage. But thanks to watermarks, this useful technique becomes more prone to error.

When interpreting and sharing open source content, it is critical that we do not edit the footage in a way that diminishes, removes, or obscures useful information contained in that content. Even if you think you are not obscuring critical information, there is no way to know if the information you altered would be helpful later.
For example, the audio contained in the footage of the shooting of Columbian journalist Abelardo Liz contained vital clues that allowed us to geolocate where the gunfire came from. If this footage was edited over with a dramatic audio track, it would have concealed a vital component of this investigation.
7. Racing to be First at Any Cost
It is easy to get wrapped up in the whirlwind of breaking news, especially around terror attacks and military conflict. The incentives of social media platforms, where the bulk of public open source research is carried out, encourage this behaviour. There is a big temptation to be the first person to make a ‘breakthrough’ in a developing story, or to quickly generate an analysis on an event.
However, validating content should always take priority over speed.
Some of the most high-profile and damaging examples of this are the many times that amateur investigators misidentified innocent people as the perpetrators of terror attacks. This occurred recently with the Bondi Junction stabbing, as well as the Boston Marathon bombings in 2013 and the Allen, Texas mall shooting in 2023. These kinds of mistaken results have been based on the innocent person having the same name or a similar looking face as the perpetrator — neither of which is sufficient evidence alone given the gravity of such identifications.
Too often, verification gets overlooked when the desire for speed is prioritised which can create more harm and confusion about an unfolding situation rather than bringing the facts and clarity needed.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Instagram here, X here and Mastodon here.