Gaming Meets OSINT: Using Python to Help Solve Her Story
Translations:

This was originally posted to the AutomatingOSINT.com blog.
There is a very cool game called Her Story. The premise is that you are a cop sitting in front of a 1990s-era computer system that enables you to punch keywords in to view videos about a murder case. When you punch in a keyword, there are only 5 videos that can be shown, so you have to do a relatively good job of keeping notes of what keywords you have entered and how to combine them to continue accessing new material in the database. The story is good, and it quickly becomes addictive as you try to keep pushing the case along. If you haven’t played it, take the 2 – 3 hours and go and do so, then come back. You won’t be disappointed. The folks at Wired loved it and so did I.
WARNING: You will most definitely see some spoilers below if you don’t play the game in advance. Hate mail accepted.
Done?
So the thing is that once you have wrapped the game (do people still say “wrapped”?) you will be left wondering if you managed to view all of the videos. If you are like me, there were a pile of lingering questions about who Hannah and Eve are (are they the same person?), were there clues I missed? Was Simon a drunk or just a filanderer? The nearest thing I could find on some forums was that you could enter a special command: ADMIN_RANDOM which would randomly pull up videos for you until you had viewed all of them but this seemed a bit hokey. The hacker in me wanted to try to figure out how I could actually punch in all supported keywords to view the videos I missed, and I thought it would be interesting to begin visualizing how keywords are mapped to one another and how they are tied to a particular video. Let’s see what we can do.
Closed Captioning
If you played the game (you did play the game right?) you know that each of the videos has closed captioning. The first thing I did was drop into the directory where the game was installed and I started hunting around for the video files. My theory was this: if the videos had the closed captioning encoded in separate text files, then the raw video files should not show any text in them. A quick search in my terminal yielded this (I am on Mac OSX and used Steam for the game):
Her Story.app/Contents/Resources/Data/StreamingAssets
Inside of this directory was a pile of .m4v video files, once I double-clicked on one I saw a video like the following:
Aha! No closed captioning text to be seen. So this means that the text for the captions have to be pulled in from another source, and if we’re super lucky, that source won’t be encrypted. Simon was the victim of the crime (you DID play the game right?!), so I started by searching for his name in all of the files inside the game directory. A grep from the main HER STORY.app directory yielded me this:
Justins-MacBook-Pro:Her Story.app justin$ grep -r -i “simon” .
Binary file ./Contents/Resources/Data/sharedassets1.assets matches
Justins-MacBook-Pro:Her Story.app justin$
Well this looks promising doesn’t it. I copied the sharedassets1.assets file to my Desktop and cracked it open with Synalize It! (thanks to Zach Cutlip for the recommendation). The first thing I did was perform a quick search for the string Simon:

And it gave me some results. When I double-clicked on the first result, I could see what looked like the actual closed captioning text for the videos!

This looks really promising. Let’s take a closer look at the hex dump to see what makes up a record:

Ok so my guess at this point is that the comma separated values are fields for the closed captioning:
Field 1: Character. (EVE)
Field 2: No idea. (1)
Field 3: The text of the captioning, perhaps for keyword matching.
Field 4: The length of the video (7 seconds)
Field 5: The video ID (101) – validated by playing the video
Field 6: The text of the captioning matched to the time in the video when it is to be displayed.
The rest of the fields I have no idea what they mean and then it appears that the video record is delimited by 0x0D 0x0A and then you can see the next closed captioning record being shown. Let’s write some Python to extract each of these video records to test the theory out. Open up her_story_text.py (grab the source code from here) and punch in the following code:
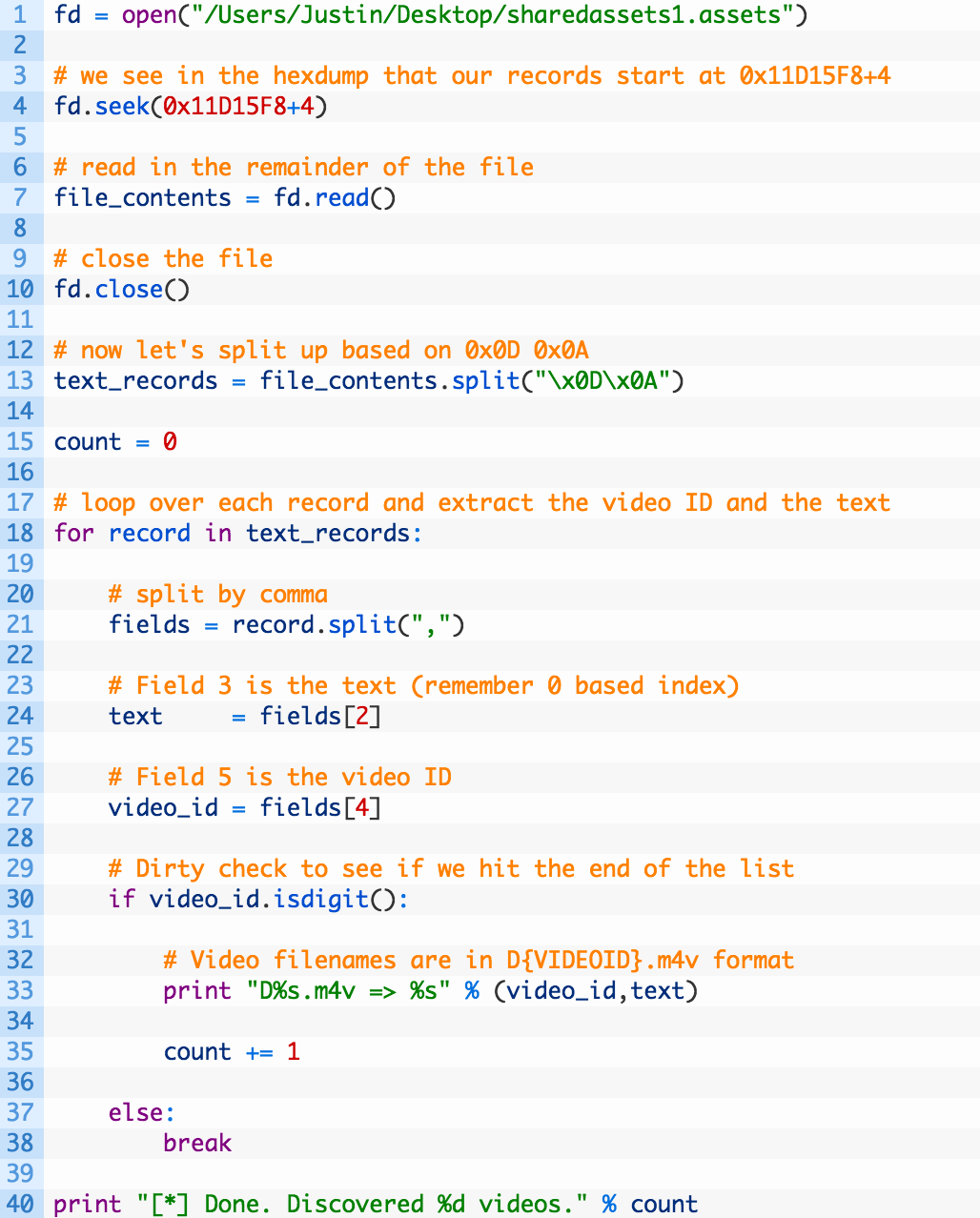
Cool so this is a tiny little script that does the following:
- Line 1: open the shared assets file that has the text in it. Adjust this to suit the path to your file.
- Line 4: we are seeking to where we know that the captions start in the file rather than reading the whole file in. This offset is derived from looking at our hex editor.
- Line 13: we split each record based on the 0x0D 0x0A delimiter, this should give us the captions we want.
- Lines 18-38: we simply walk over the list of records (18), we split again based on commas (21), and then extract the text (24) and video ID (27). We do a quick test to see if we have a valid video ID (30) and then output the results (33).
Beauty. Let’s give it a run and take a look at the output.
D101.m4v => A black coffee thanks. No sugar. I’m sweet enough as it is.
D102.m4v => My name is Hannah. H-A-N-N-A-H. It’s a palindrome. It reads the same backwards as forwards. It doesn’t work if you mirror it though it’s not quite symmetrical. But well well you get the idea. Sorry! Hannah Smith. I live at thirty one Gladstone Street.
D103.m4v => Simon. Simon Smith. He works at Ernst Brothers Glass. They do windows all kinds of glass. Simon does the more special work. Mirror making feature windows. Artistic things. Really beautiful things.
…
[*] Done. Discovered 271 videos.
So you could totally stop here, and if you read through each of the text captions in order, it really fills some of the gaps that you might have had after you played the game. I know it did for me.
Visualizing Keywords to Video Relationship
Alright, so the first step is done. We have all of the text and the associated videos. Now what would be awesome is to visualize how the keywords map to videos. We are going to modify our previous code to return a dictionary that is keyed by video ID and have its value set to the text of that video. We’ll then use a very simple text processing technique to split the text into keywords. The final touch will be to use networkX to generate ourselves a graph.
Prerequisites
pip install networkx
Download Gephi
Let’s get started! Crack open her_story_graph.py (grab the source here) and hammer out the following code:
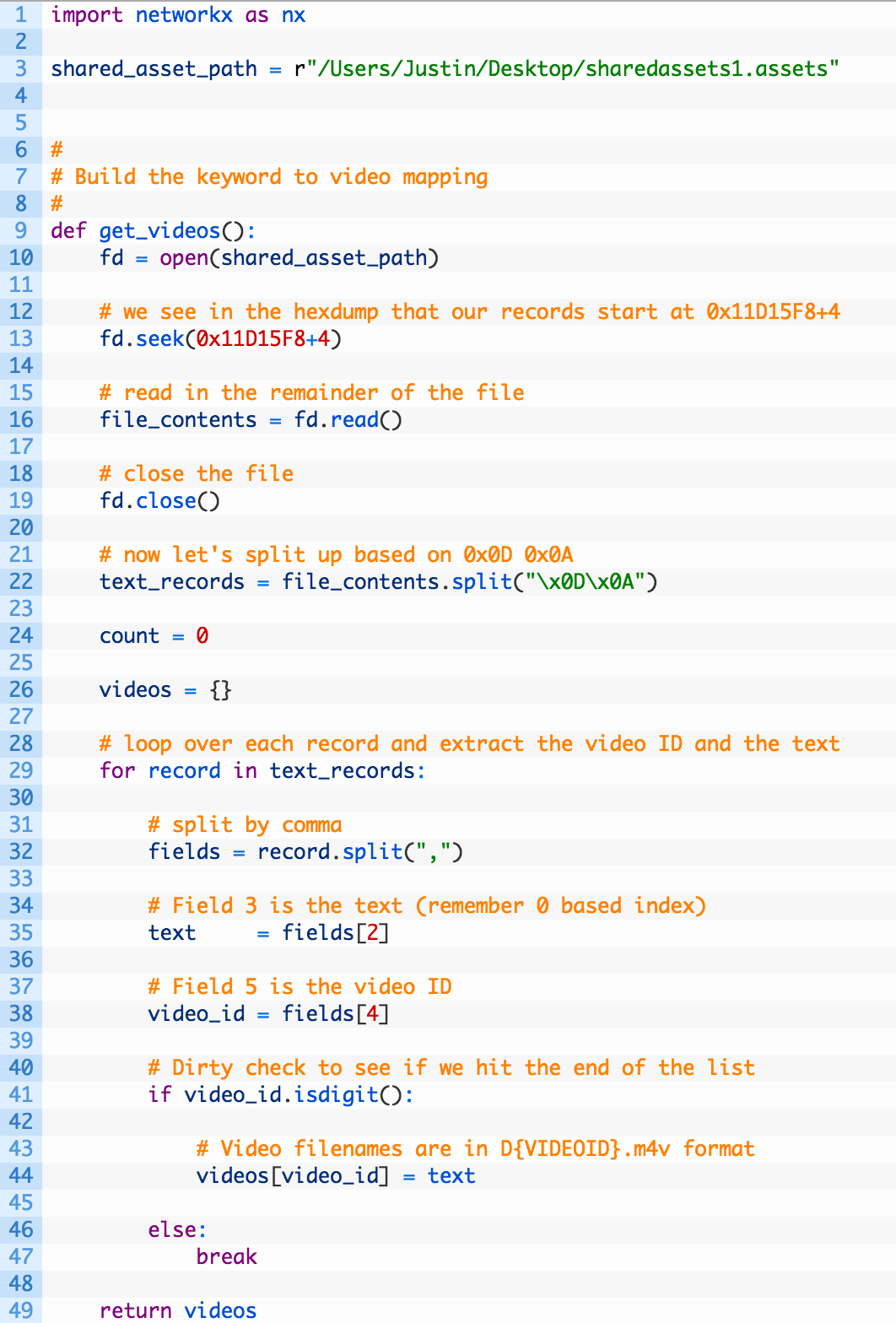
Ok let’s look at the important pieces here:
- Line 3: the path to the shared assets file, make sure you are backing this up into your Desktop for fear of corrupting your Her Story install.
- Lines 26-49: we setup a dictionary to store the video IDs (26) and it’s associated text (46) before returning it (49).
This code is pretty much like our previous code except for setting up the dictionary and making it a pretty function. Now let’s implement some simple text processing and some graphing action. Add the following code:
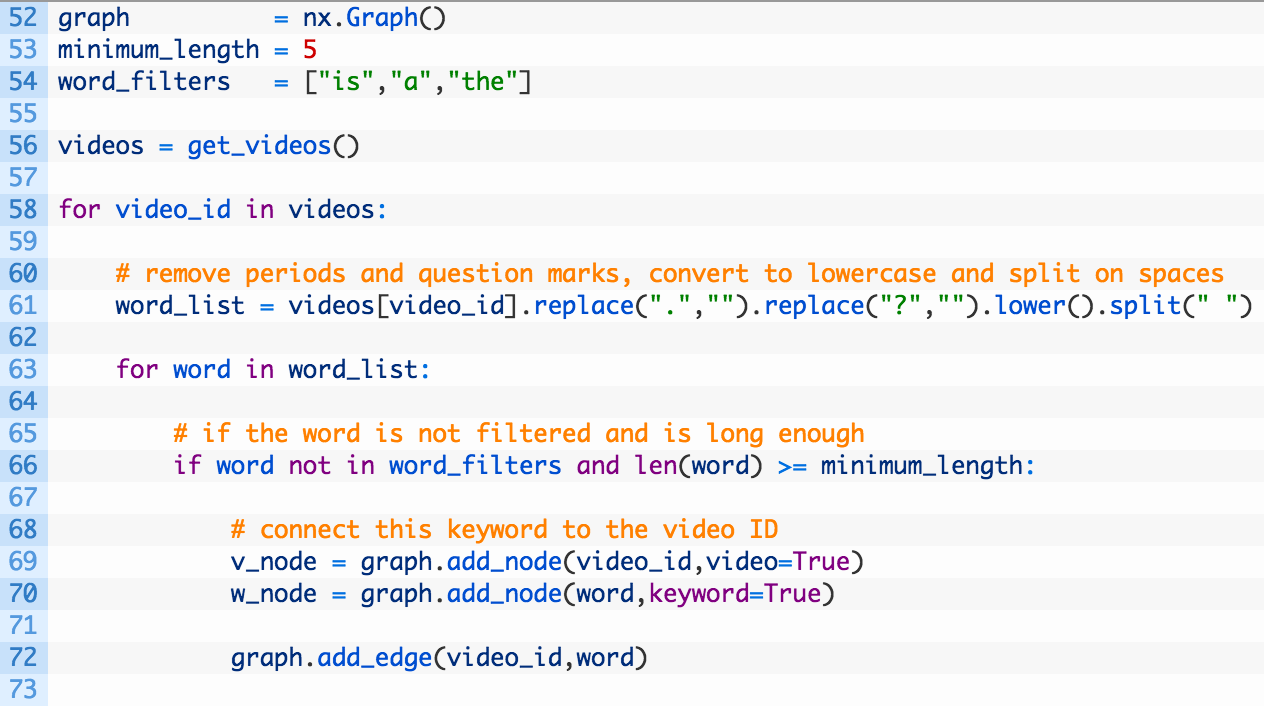
Ok this is a bit more interesting!
- Line 52: initialize our networkX graph object.
- Lines 53-54: here we are defining a maximum word length of 5 and setting up a word filter list of garbage words we don’t want included. You can adjust the numbers and the filter list to experiment.
- Line 56: we call our get_videos function to get back our dictionary of videos mapped to text.
- Line 61: as we iterate over the list of videos we take the text, remove punctuation (there are no commas in the closed captioning), and then split the captioning into individual words based on the space character.
- Lines 66-72: we walk through the list of words we split out and if the word is not less than 5 characters and is not in the filter list (66) we add the video ID to the graph (69), add the keyword to the graph (70) and then connect the two with an edge (72). Notice when we add the nodes to the graph that we assign attributes to them called “keyword” and “video”. You’ll see why this is shortly.
- Line 75: once we have created our fancy graph object we write it out to a GEXF file that Gephi can understand.
Very cool stuff. If you are new to Gephi, watch the video below where I load the GEXF file, layout the graph, color the nodes and do some brief exploration.
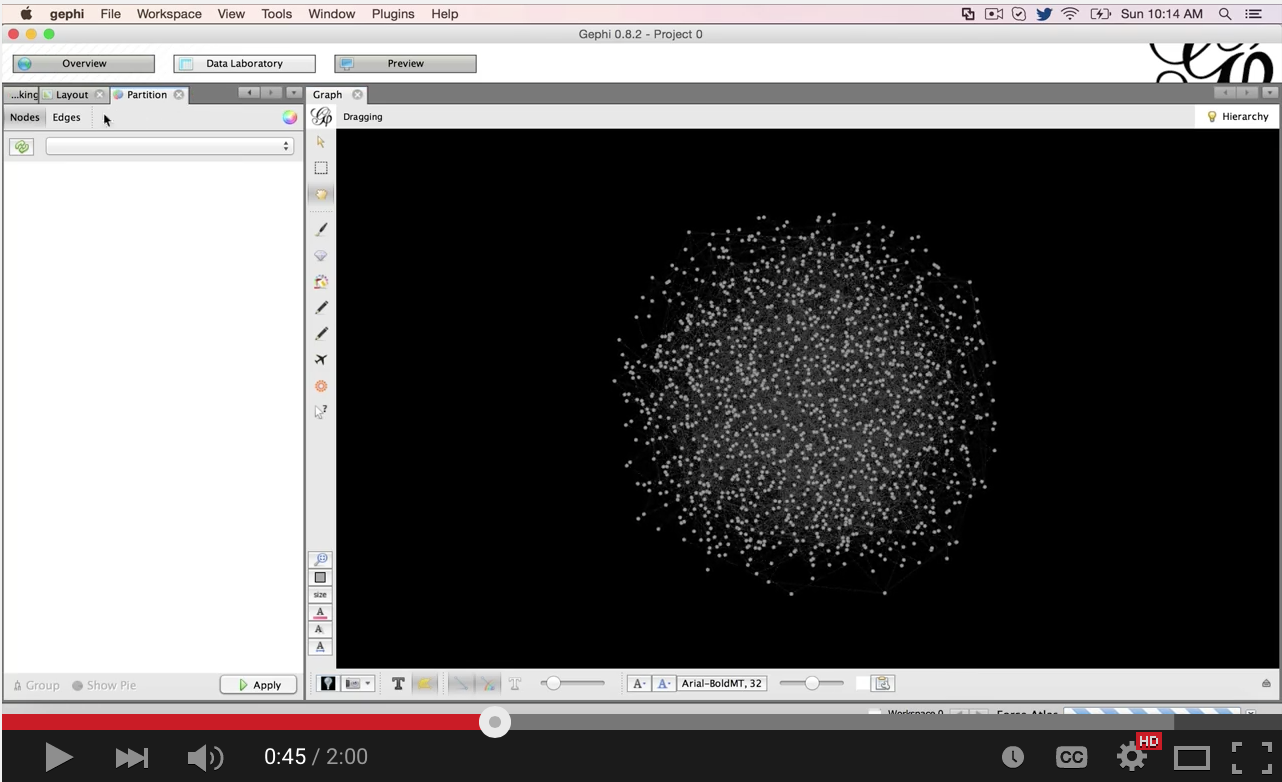
How frickin’ cool is that? But there is some obvious improvement. We know that we are limited in our search terms so the last node in the graph we explored was the word “there”. That is not going to be that useful for us. Let’s do a little better.
Smarter Visualization Using Topia
My good buddy Pete Markowsky recommended a natural language processing module called topia. Topia will do the work of extracting the useful pieces of information from text. In particular, I am interested in only pulling out the nouns and proper nouns from the text and then mapping those to the videos. This should give us a much cleaner graph to work with, and give us much more relevant search terms to use in the game.
Prerequisites
pip install topia.termextract
Let’s create our new and improved grapher. Open a new file calledher_story_graph_tagged.py (download source here) and punch in the following code:
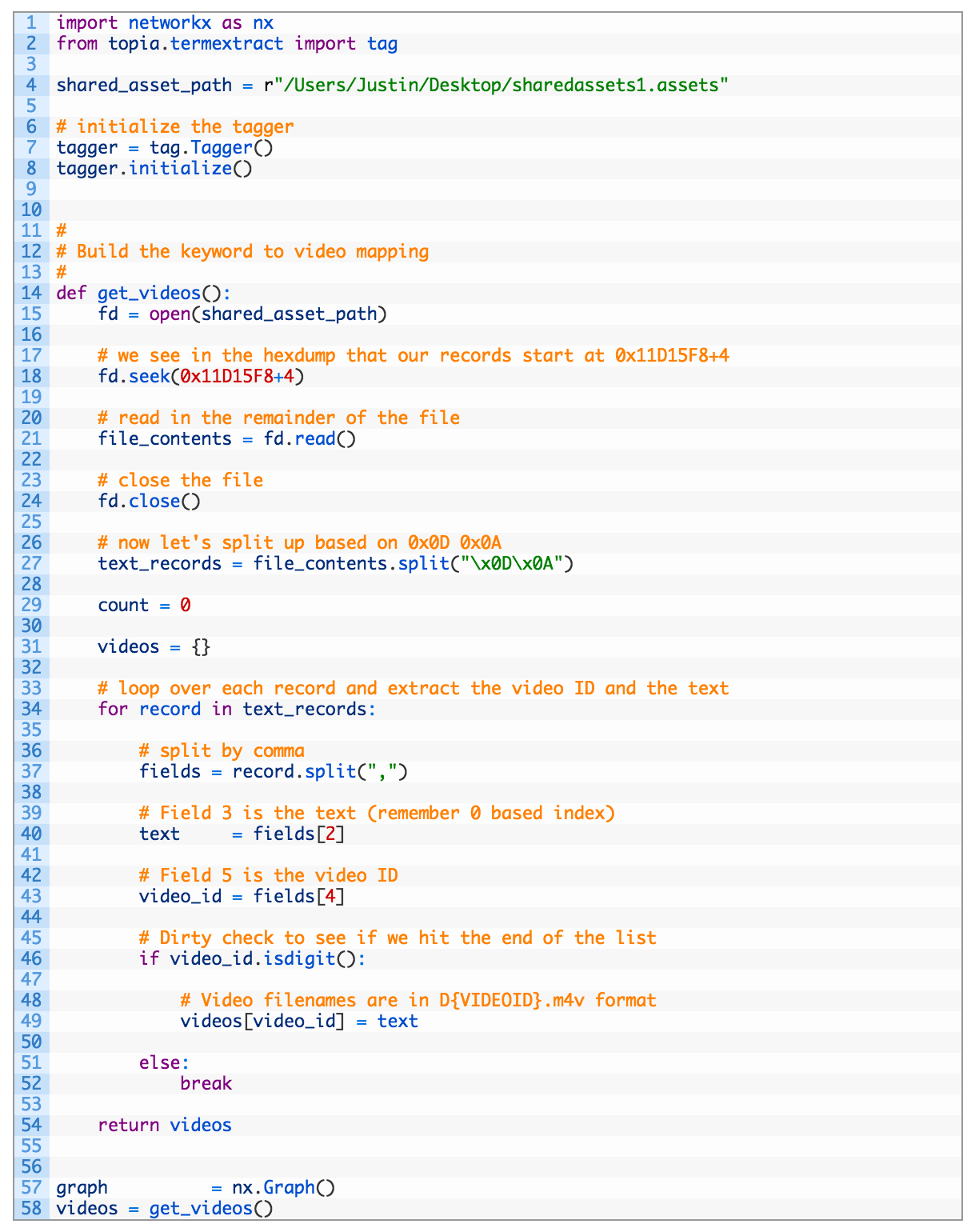
Not a lot new so far with the exception of our topia import and initialization. Most of you will do a quick copy/paste of the previous code, and I encourage you to do so.
Now let’s add the real meat of the script in:
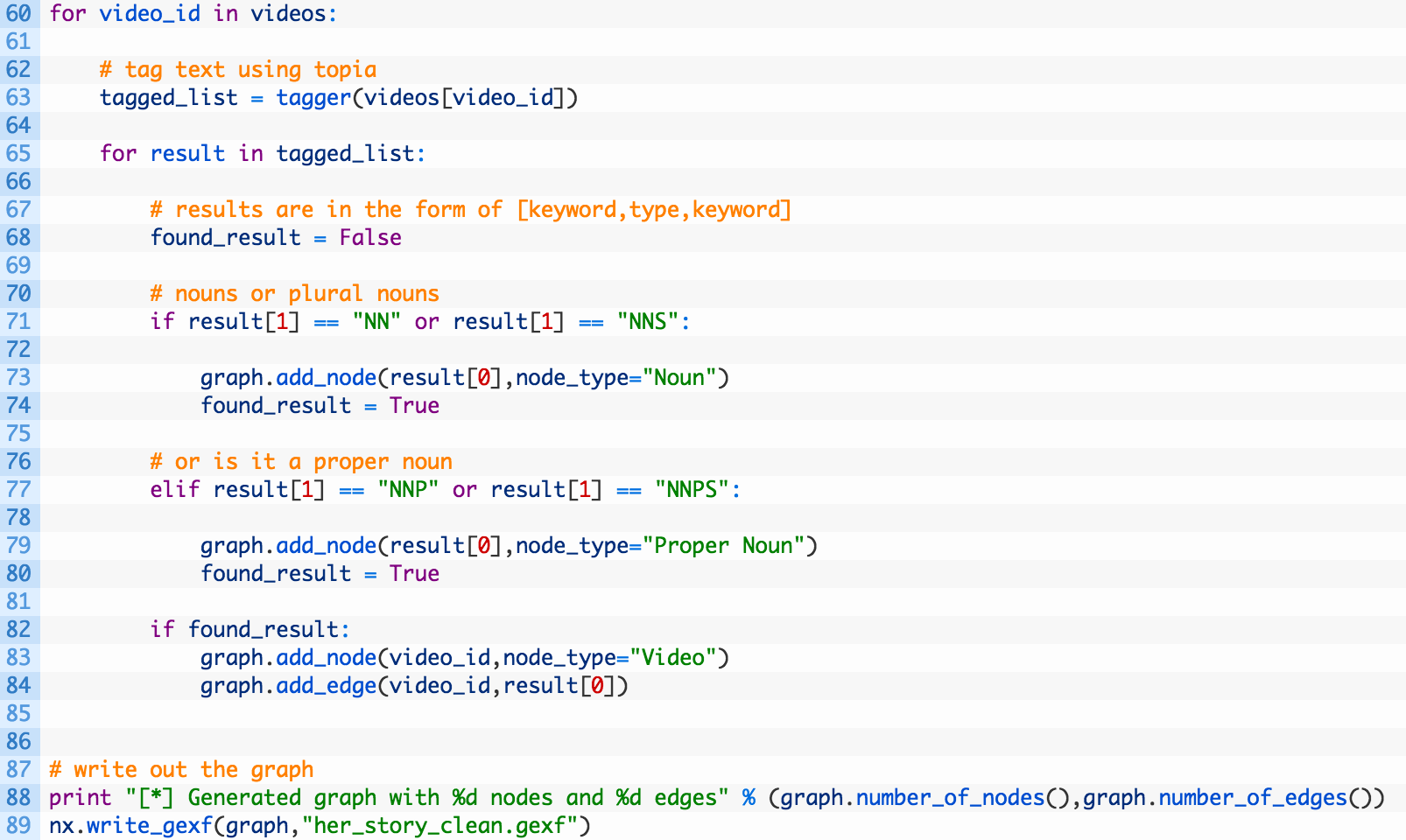
Ok so this definitely looks different!
- Line 63: we use our topia tagger to process the text for the current video ID. This will return a list that tells us the word that was tagged, as well as the part of speech tag. A part of speech tag will tell us what a noun, verb, adjective, etc. is. For a listing of all tags see this link. We are interested in nouns (NN), plural nouns (NNS), proper nouns (NNP) and plural proper nouns (NNPS).
- Lines 71-81: we walk through the list of results, and if we see a word that matched our desired tag we add that word to the graph and set anode_type attribute to tell us what the tag was. We then tie the word to the video ID by connecting them with an edge (84).
- Line 89: we output the graph in the GEXF format, just denoting it is more awesome by adding _clean to the filename.
Give it a spin and you should see that it generates fewer nodes and edges because we have eliminated a lot of the cruft from our dataset. Let’s get back into Gephi and have a look!
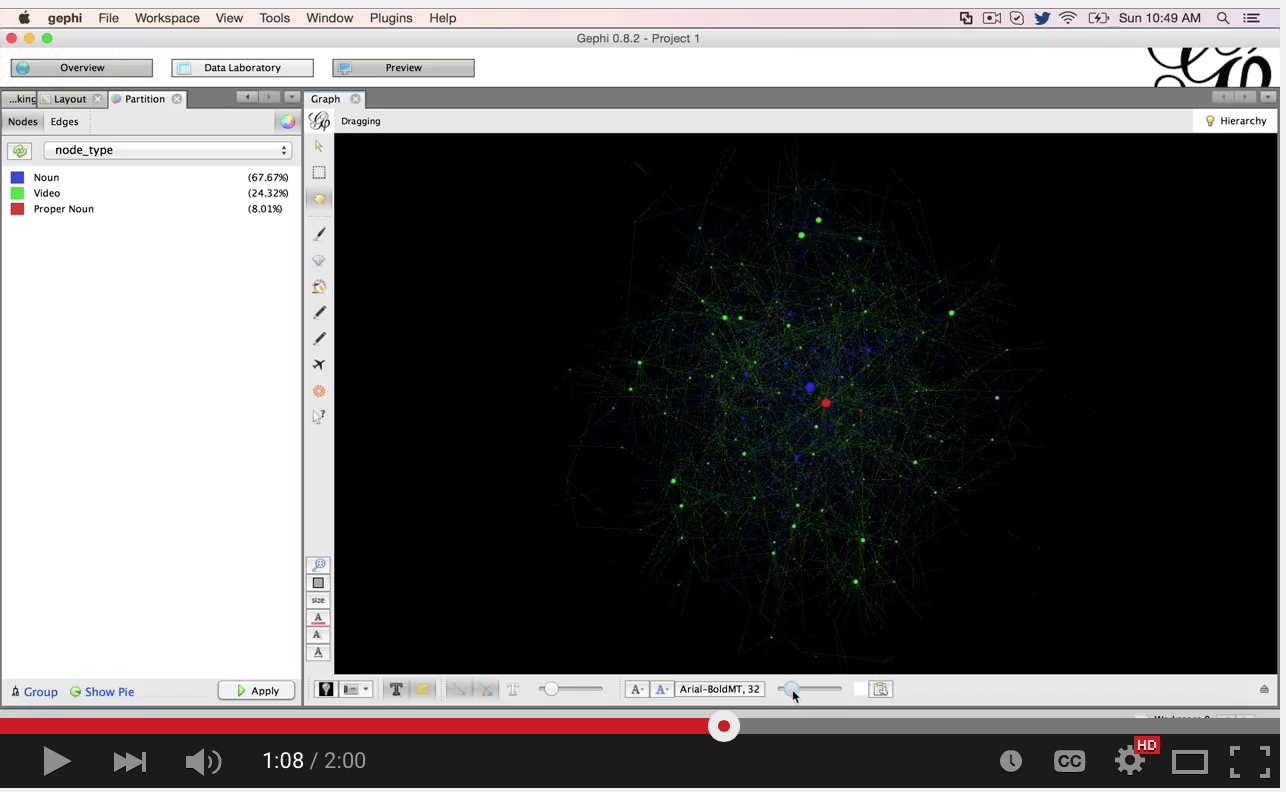
Beautiful. This gives us all kinds of views into this data, and how we can perform searches to view particular videos.
WTF
Ok so you might have reached the end of this post and wondered what this has to do with OSINT. There are a few takeaways here:
- Not Everything Has an API – a little reverse engineering know-how, even with a hex editor can help you pull data from seemingly closed sources. Weird documents, or pieces of data from custom applications can yield text for doing investigations.
- Visualization and Text Analysis – imagine this wasn’t a game but a large collection of documents. You would be able to write code to begin asking questions of the data, and then to visualize those results to help derive meaning. See my previous post on Bin Ladin’s Bookshelf to see how you could marry the two techniques.
Hopefully this was a fun exercise for you, I know it was for me. Unfortunately, I am still left with lingering questions, which I think is exactly how Sam Barlow wanted it.
Bonus: Build the Game in Python
Graphs are cool and all, but what I wanted was a way to quickly search and play videos to test out my theories from the visualizations and to circumvent the 5 video maximum restriction. So I wrote a commandline app that will do that for you. I am not going to walk you through the code but you can download it from here.
Homework
Ok so you could really have some fun with this. Here were a few things that I thought about doing in the future, hopefully someone beats me to it:
- use networkx to determine the paths between keywords and videos to solve the game;
- use some fancy algorithm (maybe genetic?) to attempt to solve the game.
If you do either of these, please let me know!